微軟亞洲研究院的數學與人工智能研究團隊近日取得了一項新的技術突破,他們專為解決數學問題設計并開發了名為rStar-Math的技術。這項技術于1月10日通過官方博文正式對外公布。
與微軟此前推出的Phi-4技術相比,rStar-Math采用了蒙特卡洛樹搜索(Monte Carlo Tree Search)進行推理。這種方法模擬了人類逐步解決問題的思維方式,通過將復雜問題分解成更小的部分,逐步求解,從而提高了解決數學問題的效率。
在開發過程中,研究團隊要求模型輸出自然語言描述和Python代碼形式的“思維鏈”步驟,并將自然語言作為Python代碼的注釋。他們僅使用Python代碼輸出進行訓練,這一做法旨在使模型更加清晰地展示其解題過程。
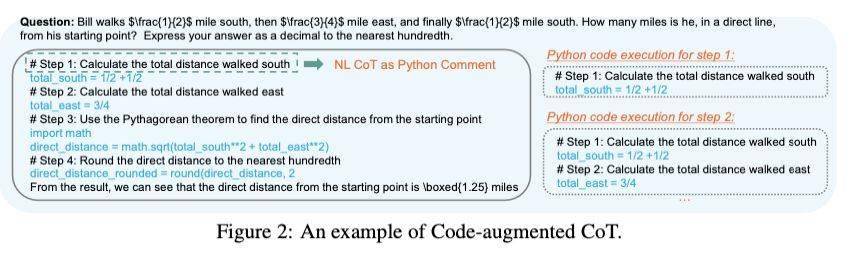
為了進一步提升模型的性能,研究團隊還訓練了一個“策略模型”來生成數學推理步驟,并使用“過程偏好模型”(PPM)來選擇最有希望的解題步驟。這兩個模型通過四輪“自我進化”相互改進,不斷優化其解題能力。
在訓練過程中,研究團隊使用了74萬道公開的數學應用題及其解答作為初始數據,并利用上述兩個模型生成了新的解題步驟。這一做法不僅豐富了訓練數據,還有助于模型更好地理解和解決數學問題。
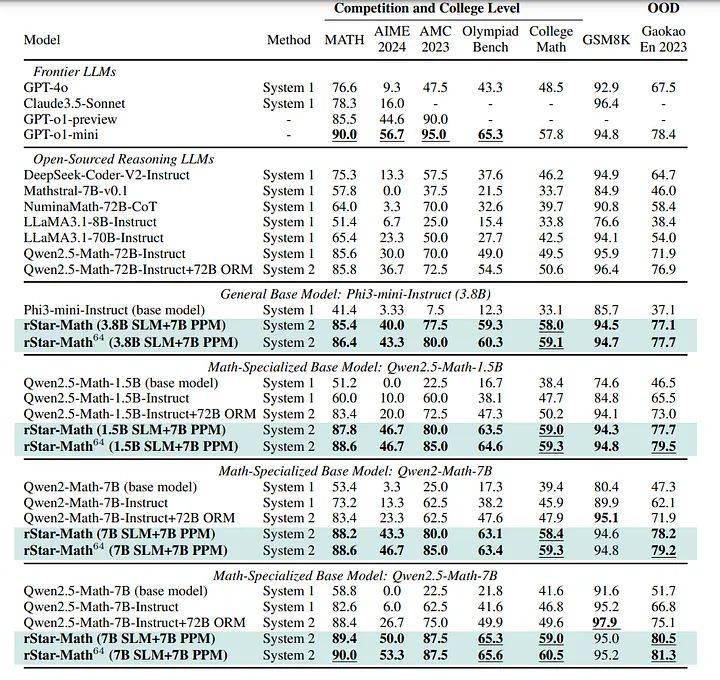
測試結果顯示,應用rStar-Math技術后,Qwen2.5-Math-7B模型的準確率從58.8%躍升至90.0%,Phi3-mini-3.8B模型的準確率也從41.4%提升到86.4%。與OpenAI的o1-preview模型相比,rStar-Math技術在兩個模型上的表現分別高出4.5%和0.9%。
為了讓其他研究者能夠使用和改進rStar-Math技術,研究團隊已在Hugging Face上宣布,他們計劃將rStar-Math的代碼和數據在GitHub上公開。這一舉措將促進數學與人工智能領域的交流與合作,推動相關技術的進一步發展。