在邁向通用人工智能(AGI)的征途上,具身智能技術(shù)的突破與應(yīng)用被視為不可或缺的一環(huán)。全球科技巨頭紛紛加速布局,特斯拉的Optimus、Agility Digit、波士頓動力的Atlas以及Figure AI等機(jī)器人項目層出不窮,而在今年的蛇年春晚,機(jī)器人“扭秧歌”的趣味表演更是成為了街頭巷尾的熱門話題。隨著大模型技術(shù)的不斷精進(jìn),具身智能迎來了前所未有的發(fā)展機(jī)遇。
然而,在國內(nèi)眾多企業(yè)與高校推動具身智能技術(shù)發(fā)展的過程中,一個核心挑戰(zhàn)始終如影隨形——如何在有限的具身數(shù)據(jù)下,使機(jī)器人能夠靈活適應(yīng)復(fù)雜場景,并實現(xiàn)技能的高效遷移。為了攻克這一難題,京東探索研究院的李律松、李東江博士團(tuán)隊攜手地瓜機(jī)器人秦玉森團(tuán)隊、中科大徐童團(tuán)隊、深圳大學(xué)鄭琪團(tuán)隊、松靈機(jī)器人及睿爾曼智能吳波團(tuán)隊,共同發(fā)起了一項創(chuàng)新項目。該項目得到了清華RDT團(tuán)隊在baseline方法上的技術(shù)支持,旨在探索一種全新的解決方案。
項目團(tuán)隊提出了一種基于三輪數(shù)據(jù)驅(qū)動的原子技能庫構(gòu)建框架,這一創(chuàng)新方法突破了傳統(tǒng)端到端具身操作的數(shù)據(jù)瓶頸。通過該框架,可以動態(tài)地自定義和更新原子技能,并結(jié)合數(shù)據(jù)收集與VLA(視覺-語言-動作)少樣本學(xué)習(xí)技術(shù),高效構(gòu)建技能庫。實驗結(jié)果顯示,該方案在數(shù)據(jù)效率和泛化能力方面均表現(xiàn)出色,為具身智能領(lǐng)域帶來了革命性的突破。
具身智能,即讓機(jī)器人具備身體感知與行動能力的人工智能,在生成式AI時代迎來了重要的發(fā)展契機(jī)。通過跨模態(tài)融合技術(shù),將文本、圖像、語音等數(shù)據(jù)映射到統(tǒng)一的語義向量空間,為具身智能技術(shù)的發(fā)展提供了新的動力。然而,現(xiàn)實環(huán)境的復(fù)雜性使得具身操作模型在泛化性上面臨巨大挑戰(zhàn)。端到端的訓(xùn)練方式雖然直觀,但依賴海量數(shù)據(jù),容易導(dǎo)致“數(shù)據(jù)爆炸”問題,限制了VLA技術(shù)的發(fā)展。
為了解決這一問題,項目團(tuán)隊提出了基于三輪數(shù)據(jù)驅(qū)動的原子技能庫構(gòu)建方法。該方法能夠在仿真或真實環(huán)境的模型訓(xùn)練中顯著減少數(shù)據(jù)需求。通過VLP(視覺-語言-規(guī)劃)模型將任務(wù)分解為子任務(wù),并利用高級語義抽象模塊將子任務(wù)定義為通用原子技能集。隨著三輪更新策略的動態(tài)擴(kuò)展,技能庫不斷擴(kuò)增,覆蓋的任務(wù)范圍也越來越廣。這一方法將重點從端到端技能學(xué)習(xí)轉(zhuǎn)向了細(xì)顆粒度的原子技能構(gòu)建,有效解決了數(shù)據(jù)爆炸問題,并提升了機(jī)器人對新任務(wù)的適應(yīng)能力。

從產(chǎn)業(yè)落地角度來看,具身操作是機(jī)器人實現(xiàn)智能化的關(guān)鍵模塊。然而,現(xiàn)有的端到端VLA模型在進(jìn)行高頻開環(huán)控制時,即便中間動作失敗,仍會輸出下一階段的控制信號。這導(dǎo)致VLA模型在高頻控制機(jī)器人或機(jī)械臂時,強(qiáng)烈依賴于VLP提供的低頻智能控制來指導(dǎo)階段性動作生成,并協(xié)調(diào)任務(wù)執(zhí)行節(jié)奏。為此,項目團(tuán)隊構(gòu)建了集成視覺感知、語言理解和空間智能的VLP Agent,以統(tǒng)一訓(xùn)練與推理的任務(wù)分解。
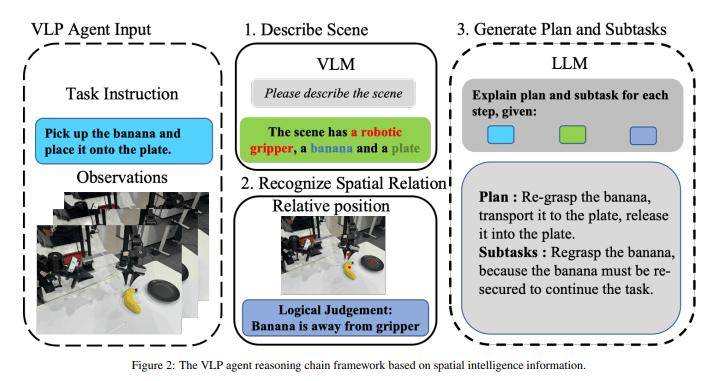
VLA技術(shù)雖然取得了顯著進(jìn)展,但仍存在一些問題。隨著技術(shù)的發(fā)展,VLA模型從專用數(shù)據(jù)向通用數(shù)據(jù)演進(jìn),機(jī)器人軌跡數(shù)據(jù)已達(dá)百萬級別;模型參數(shù)規(guī)模也從千億級向端側(cè)部署發(fā)展。然而,在通用機(jī)器人應(yīng)用中,人為定義端到端任務(wù)容易導(dǎo)致任務(wù)窮盡問題。物品位置泛化、背景干擾、場景變化等仍是主要挑戰(zhàn)。即便強(qiáng)大的預(yù)訓(xùn)練模型,也需要大量數(shù)據(jù)來克服這些問題。項目團(tuán)隊提出的三輪數(shù)據(jù)驅(qū)動的原子技能庫方法,結(jié)合SOTA VLA模型,通過高級語義抽象模塊將復(fù)雜子任務(wù)映射為結(jié)構(gòu)化原子技能,有效提升了VLA模型的泛化性和可塑性。

原子技能庫的構(gòu)建旨在降低數(shù)據(jù)采集成本,同時增強(qiáng)任務(wù)適配能力,提升具身操作的通用性,以滿足產(chǎn)業(yè)應(yīng)用需求。通過基于數(shù)據(jù)驅(qū)動的原子技能庫構(gòu)建方法,結(jié)合端到端具身操作VLA與具身規(guī)劃VLP,項目團(tuán)隊成功構(gòu)建了一個系統(tǒng)化的技能庫。這一技能庫能夠動態(tài)擴(kuò)增,適應(yīng)的任務(wù)范圍也不斷增加。相比傳統(tǒng)的TASK級數(shù)據(jù)采集,提出的原子技能庫所需要的數(shù)據(jù)采集量顯著下降,同時技能適配能力得到了大幅提升。