字節(jié)跳動旗下的Seed團隊近期公布了一項重大技術(shù)進展,他們宣布開源了一個名為BAGEL的統(tǒng)一多模態(tài)理解與生成模型。這一模型能夠同時處理文本、圖像和視頻數(shù)據(jù),實現(xiàn)跨模態(tài)的信息交互與生成。
據(jù)悉,BAGEL模型擁有70億個激活參數(shù)(總參數(shù)量達到140億),并在海量交錯多模態(tài)數(shù)據(jù)上進行了深度訓練。在多項標準測試中,BAGEL的表現(xiàn)超越了當前頂尖的開源多模態(tài)模型,如Qwen2.5-VL和InternVL-2.5,甚至在文本到圖像的生成質(zhì)量上,也能與專業(yè)級生成器SD3相媲美。
除了在多模態(tài)理解方面取得突破,BAGEL在圖像編輯領(lǐng)域同樣展現(xiàn)出了非凡的能力。它不僅在經(jīng)典編輯場景中優(yōu)于其他開源模型,還進一步擴展到自由形式的視覺操作、多視圖合成以及世界導航等高級任務(wù)。這些能力標志著BAGEL在“世界建模”這一前沿領(lǐng)域邁出了重要一步。

BAGEL基于先進的大語言模型進行訓練,因此具備基礎(chǔ)的推理和對話能力。它能夠接收混合了圖像和文本的輸入,并以同樣混合的格式輸出結(jié)果。這種靈活性使得BAGEL在處理復雜多模態(tài)信息時更加得心應手。
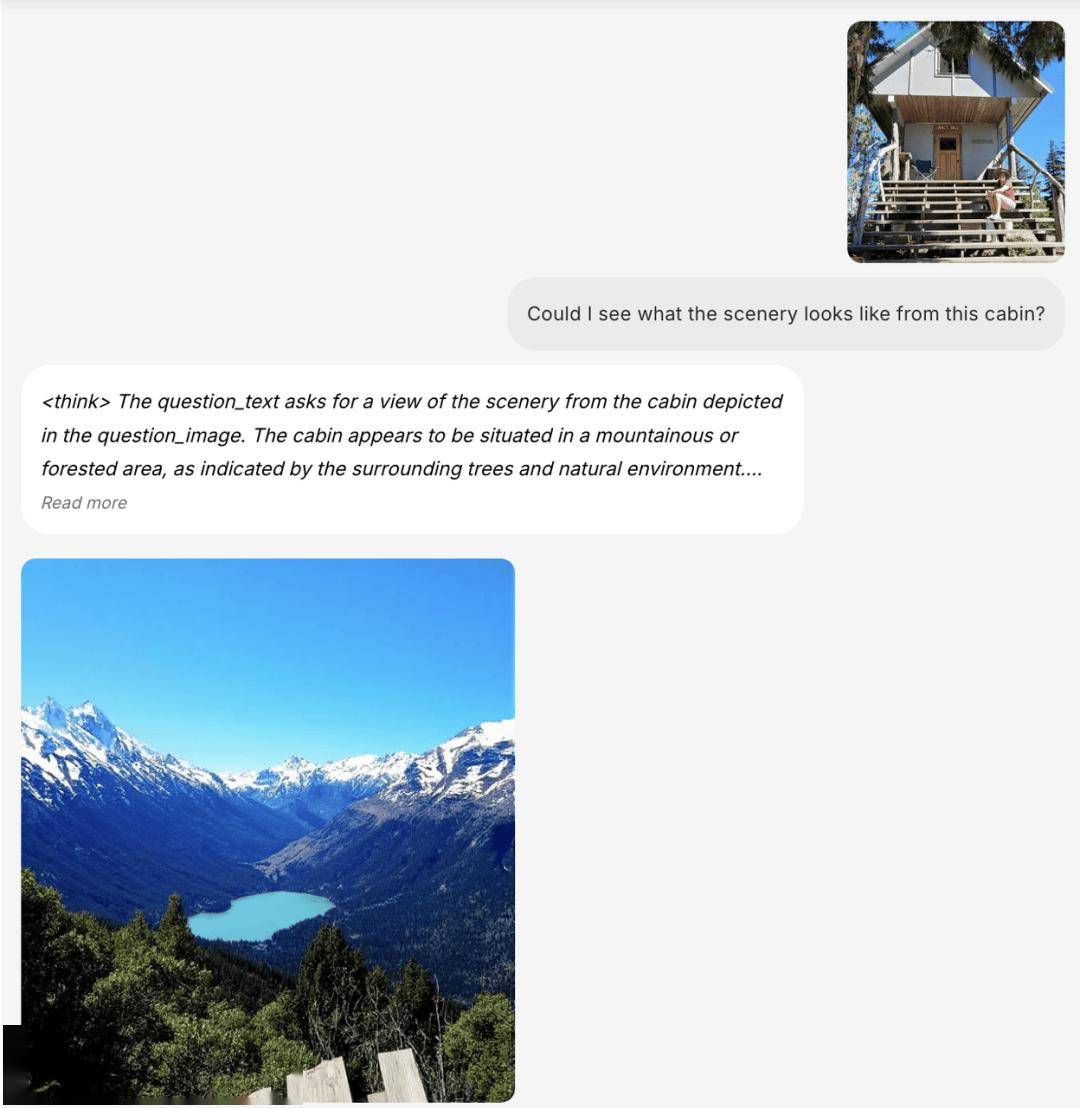
在生成高質(zhì)量、逼真的圖像和視頻方面,BAGEL同樣表現(xiàn)出色。它還引入了長思維鏈(COT)模式,使得模型在生成內(nèi)容之前能夠進行更為深入的“思考”。這種能力不僅提升了生成內(nèi)容的質(zhì)量,還增加了生成過程的可控性和可預測性。

由于在大規(guī)模交錯多模態(tài)數(shù)據(jù)上的預訓練,BAGEL自然而然地學會了保留視覺特征和細微細節(jié)。它能夠從視頻中捕捉到復雜的視覺運動,這一能力使得它在圖像編輯方面更加高效且準確。BAGEL還能基于少量對齊數(shù)據(jù)實現(xiàn)圖片風格的切換和場景轉(zhuǎn)換。


更令人矚目的是,BAGEL還具備世界模型的基礎(chǔ)能力。它能夠進行世界導航、未來幀預測以及3D世界生成等挑戰(zhàn)性任務(wù)。通過不同角度的旋轉(zhuǎn)或視角切換,BAGEL能夠展現(xiàn)出強大的泛化能力。不僅在真實場景中表現(xiàn)出色,它還能在游戲、藝術(shù)作品以及卡通動畫等虛擬環(huán)境中實現(xiàn)導航。
基于以上強大的能力,BAGEL通過一個統(tǒng)一的多模態(tài)接口,實現(xiàn)了各項能力的復雜組合和多輪對話。用戶可以通過簡單的指令,讓BAGEL完成從圖片剪切到智能編輯,再到場景轉(zhuǎn)換和風格轉(zhuǎn)換等一系列操作,極大地提升了工作效率和創(chuàng)作自由度。