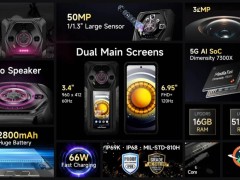
OpenAI首席執行官薩姆·奧爾特曼近期宣布,公司即將在未來數月內推出一款具備推理能力的新型開放權重語言模型,這標志著自GPT-2以來,OpenAI在開放模型領域的又一重大進展。
奧爾特曼透露,雖然這一計劃早已在醞釀之中,但由于種種優先事項,其發布被一再推遲。如今,OpenAI認為推出這一模型至關重要,它將為用戶和開發者帶來前所未有的體驗。
在正式發布前,OpenAI將按照既定框架對該模型進行全面評估,確保其性能和質量。同時,由于深知模型在發布后仍可能面臨調整和優化,OpenAI還將開展額外的工作,以確保其穩定性和可靠性。
為了收集更多來自開發者的反饋,并嘗試早期原型,OpenAI計劃舉辦一系列開發者活動。活動將從舊金山開始,隨后擴展至歐洲和亞太地區。通過這些活動,OpenAI期待與開發者們共同探討模型的潛力和應用前景。
值得注意的是,與以往OpenAI的模型不同,這款開放權重語言模型的預訓練參數將向公眾公開共享。這意味著開發人員和研究人員可以下載這些參數,在本地運行模型,并根據特定需求進行微調或將其融入自定義應用中。然而,需要提醒的是,開放權重并不等同于完全開源,訓練代碼、數據集和詳細日志可能仍保持專有或未公開狀態。
近年來,開放權重模型已成為業界關注的焦點。meta、Mistral等公司推出了Llama、Mixtral等強大模型,而DeepSeek、阿里巴巴和百川等新晉玩家也在積極推出可與之媲美的開源模型。這一趨勢不僅吸引了學術研究人員和獨立開發者的關注,也促使OpenAI重新審視其模型策略。
隨著開放權重模型的興起,越來越多的用戶開始尋求更加靈活和可定制的模型解決方案。OpenAI此次推出的新型開放權重語言模型,無疑將為用戶和開發者提供更多選擇和可能性。我們期待看到這一模型在未來能夠激發出更多創新和應用。