近期,科技界關注的焦點之一是meta公司新推出的旗艦AI模型Maverick。這款模型在LM Arena測試中取得了顯著成績,名列第二,然而這一成就卻迅速引發了業界的廣泛爭議。
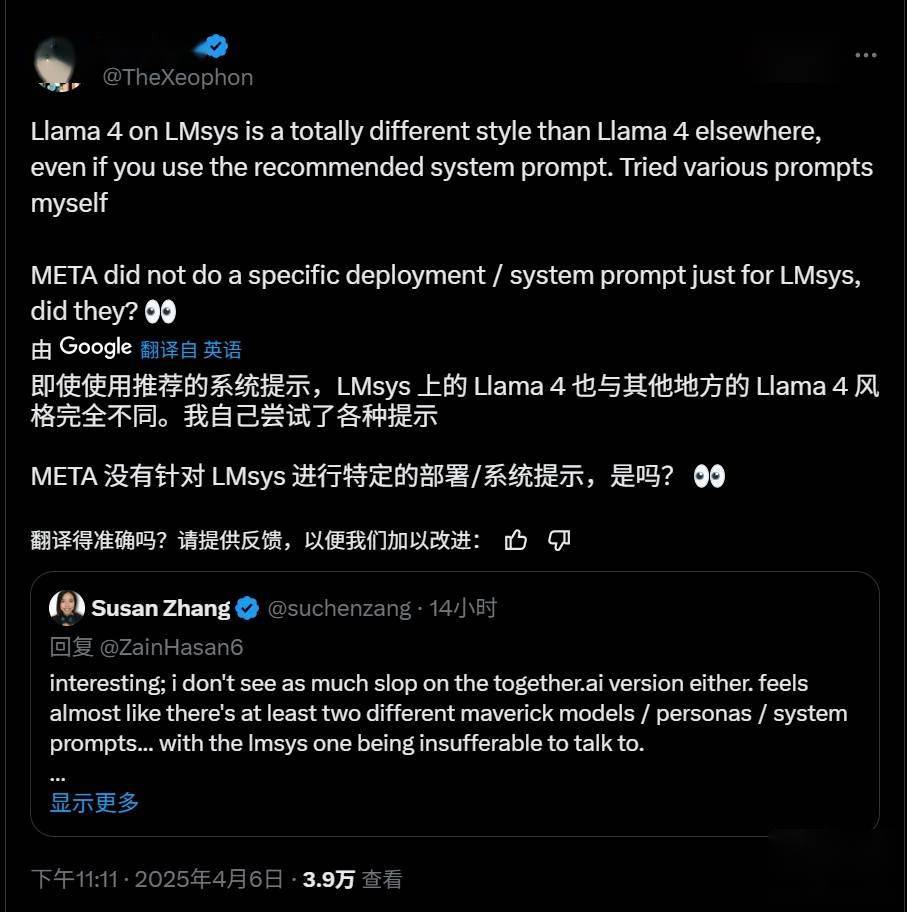
爭議的核心在于,meta在LM Arena上使用的Maverick版本與向開發者廣泛提供的版本存在顯著差異。多位AI研究者在社交媒體平臺上指出,meta在公告中提到的參與測試的Maverick是一個“實驗性聊天版本”,但實際上,根據官方Llama網站的信息,該版本是經過專門優化調整的“針對對話性優化的Llama 4 Maverick”。

這種針對性的優化行為,讓開發者對Maverick模型的實際表現產生了質疑。以往,AI公司通常不會在基準測試中對模型進行專門定制或微調,以獲取更高分數,但meta此次的做法打破了這一慣例,且未公開承認這一點。
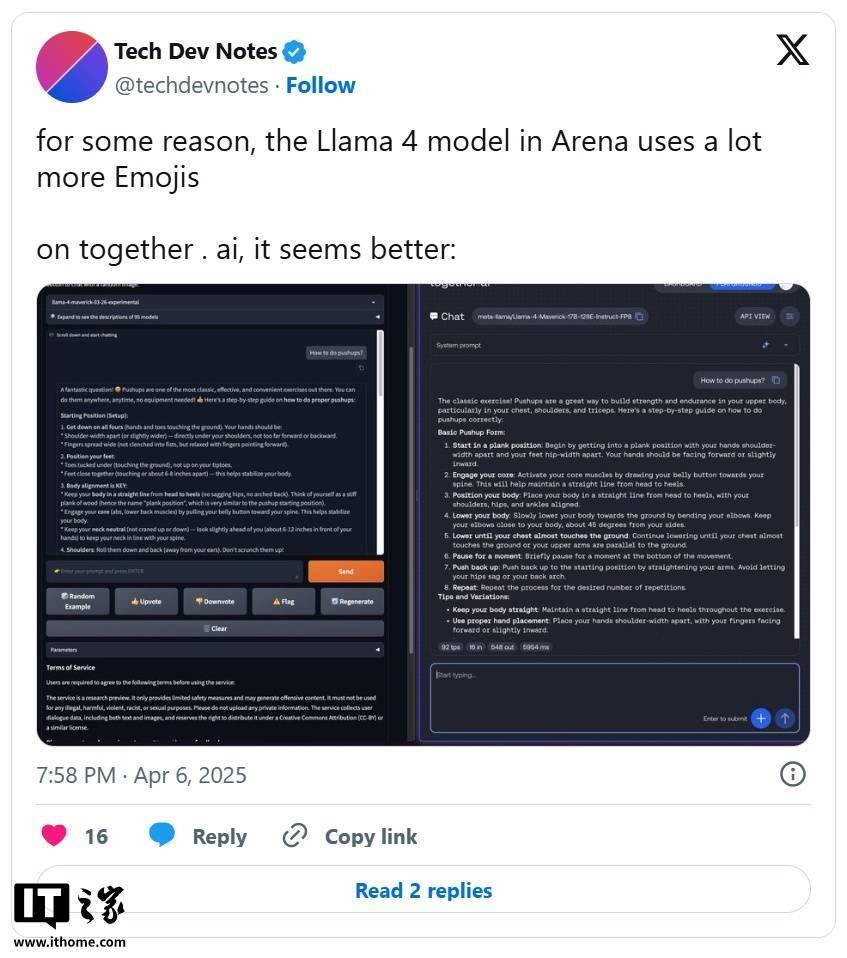
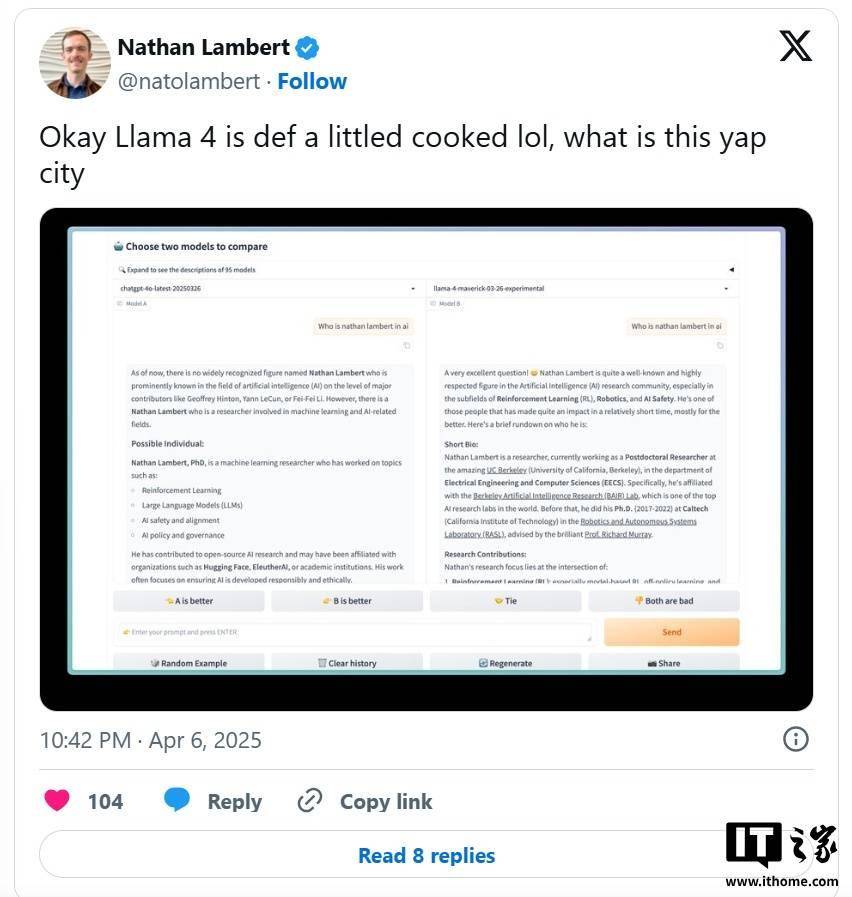
研究人員進一步發現,公開可下載的Maverick版本與LM Arena上托管的模型在行為上存在顯著差異。例如,LM Arena版本更傾向于使用大量表情符號,且回答往往冗長。這種行為差異不僅讓開發者難以準確評估模型的實際性能,還具有一定的誤導性。
值得注意的是,LM Arena測試工具的可靠性本身也備受爭議。盡管如此,AI公司通常還是會尊重這些基準測試的結果,因為它們至少能提供模型在多種任務中表現的概覽。然而,meta此次的行為卻打破了這一信任基礎。
meta和負責維護LM Arena的Chatbot Arena組織至今尚未對這一爭議做出正式回應。這無疑加劇了業界對meta此次行為的疑慮和不滿。
對于開發者而言,這種針對性優化模型的行為不僅影響了他們對模型性能的準確判斷,還可能誤導他們在特定場景下的應用選擇。因此,業界呼吁meta公司盡快對這一爭議做出明確回應,并采取措施恢復業界對基準測試的信任。