在科技界的風(fēng)頭浪尖上,DeepSeek研究團(tuán)隊(duì)攜其最新研究成果NSA(新型稀疏注意力架構(gòu))強(qiáng)勢(shì)回歸,緊隨馬斯克發(fā)布Grok 3的熱潮之后,迅速吸引了業(yè)界的廣泛關(guān)注。該團(tuán)隊(duì)通過(guò)推文宣布這一突破性進(jìn)展,短短數(shù)小時(shí)內(nèi)便收獲了超過(guò)三十萬(wàn)的瀏覽量,其熱度直逼OpenAI。
DeepSeek此次發(fā)布的論文詳細(xì)闡述了NSA的設(shè)計(jì)理念與技術(shù)細(xì)節(jié),這一創(chuàng)新機(jī)制旨在解決長(zhǎng)上下文訓(xùn)練與推理中的效率瓶頸。NSA的核心策略包括動(dòng)態(tài)分層稀疏策略、粗粒度的token壓縮以及細(xì)粒度的token選擇,這三項(xiàng)技術(shù)的結(jié)合不僅顯著降低了預(yù)訓(xùn)練成本,更在推理速度上實(shí)現(xiàn)了質(zhì)的飛躍,尤其是在解碼階段,性能提升高達(dá)11.6倍。
論文的發(fā)表也標(biāo)志著DeepSeek創(chuàng)始人兼CEO梁文鋒的親自參與,他不僅作為共同作者,還親自提交了這篇重量級(jí)論文,這一舉動(dòng)無(wú)疑為團(tuán)隊(duì)的研究增添了更多分量。
隨著AI技術(shù)的不斷進(jìn)步,長(zhǎng)上下文建模能力的重要性日益凸顯,特別是在深度推理、代碼生成及多輪對(duì)話系統(tǒng)等應(yīng)用場(chǎng)景中。DeepSeek的R1模型正是憑借其在這一領(lǐng)域的突破,能夠高效處理整個(gè)代碼庫(kù)、長(zhǎng)篇文檔,并保持對(duì)話的連貫性與復(fù)雜推理能力。然而,傳統(tǒng)的注意力機(jī)制在處理長(zhǎng)序列時(shí),因其復(fù)雜性成為了性能提升的瓶頸,尤其是在解碼長(zhǎng)上下文時(shí),softmax注意力計(jì)算幾乎占據(jù)了總延遲的70-80%。
為克服這一挑戰(zhàn),DeepSeek團(tuán)隊(duì)提出了NSA架構(gòu),通過(guò)動(dòng)態(tài)分層稀疏策略與token壓縮、選擇技術(shù),實(shí)現(xiàn)了高效的長(zhǎng)上下文建模。NSA不僅保留了全局上下文感知能力,還確保了局部精確性,并通過(guò)針對(duì)現(xiàn)代硬件的優(yōu)化,實(shí)現(xiàn)了計(jì)算速度的大幅提升,支持端到端訓(xùn)練,有效減少了預(yù)訓(xùn)練計(jì)算量。

在技術(shù)評(píng)估環(huán)節(jié),DeepSeek團(tuán)隊(duì)從通用基準(zhǔn)性能、長(zhǎng)文本基準(zhǔn)性能及思維鏈推理性能三個(gè)維度,將NSA與全注意力基線及現(xiàn)有稀疏注意力方法進(jìn)行了全面對(duì)比。結(jié)果顯示,NSA在各項(xiàng)測(cè)試中均表現(xiàn)出色,不僅預(yù)訓(xùn)練損失曲線穩(wěn)定且優(yōu)于全注意力模型,還在9項(xiàng)評(píng)測(cè)指標(biāo)中有7項(xiàng)達(dá)到最佳表現(xiàn)。特別是在長(zhǎng)上下文任務(wù)中,NSA展現(xiàn)出了極高的檢索精度與全局感知能力。
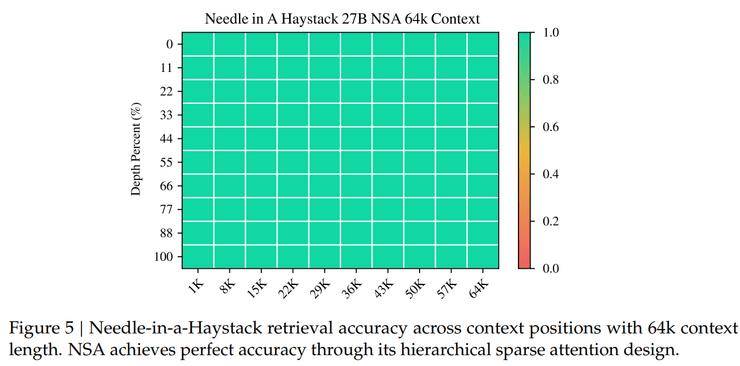
NSA的研究還驗(yàn)證了清華大學(xué)姚班早期論文中關(guān)于Transformer架構(gòu)在處理復(fù)雜數(shù)學(xué)問(wèn)題時(shí)的局限性。DeepSeek通過(guò)優(yōu)化問(wèn)題理解和答案生成,成功減少了所需tokens數(shù)量,從而得出了正確答案,而基線方法則因消耗過(guò)多tokens而失敗。這一實(shí)踐再次證明了NSA在效率和準(zhǔn)確性上的顯著優(yōu)勢(shì)。