近期,一項關于合成數據在大型模型訓練中應用的新研究成果引起了業界的廣泛關注。這項研究由谷歌、卡內基梅隆大學和MultiOn的聯合研究團隊共同完成。
據Epoch AI的研究報告顯示,盡管全球范圍內已有約300萬億個高質量的文本訓練標記可供使用,但隨著ChatGPT等大模型的快速發展,對訓練數據的需求正呈爆炸式增長。預測顯示,到2026年,現有的高質量訓練數據或將無法滿足需求。因此,探索合成數據作為替代方案顯得尤為重要。
在此次研究中,研究人員主要聚焦于兩種類型的合成數據:正向數據和負向數據。正向數據由高性能大模型(例如GPT-4和Gemini 1.5 Pro)生成,提供正確的數學問題解決方案,為模型提供學習范例。然而,單純依賴正向數據存在局限性,可能導致模型僅通過模式匹配學習,缺乏真正的理解能力,且在處理新問題時泛化能力下降。
為了克服這些挑戰,研究人員引入了負向數據,即經過驗證的錯誤問題解決步驟。負向數據的加入有助于模型識別并避免錯誤,從而提升其邏輯推理能力。盡管使用負向數據面臨諸多困難,如錯誤步驟可能包含誤導性信息,但研究團隊通過直接偏好優化(DPO)方法成功使模型能夠從錯誤中學習。
DPO方法為每個問題解決步驟分配一個優勢值,反映其相對于理想解決方案的價值。研究表明,高優勢步驟是正確解決方案的關鍵,而低優勢步驟則可能揭示模型推理中的問題。借助這些優勢值,模型能夠在強化學習框架內動態調整策略,更高效地從合成數據中學習和改進。
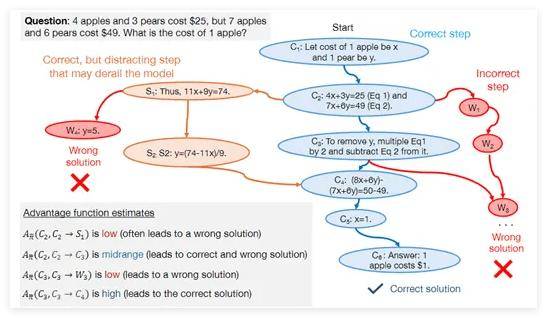
為了驗證合成數據的有效性,研究團隊選擇了DeepSeek-Math-7B和LLaMa2-7B等模型,在GSM8K和MATH數據集上進行了全面測試。測試結果顯示,經過正向和負向合成數據預訓練的大模型在數學推理任務上的性能實現了顯著提升,甚至達到了八倍的增長。這一研究成果充分展示了合成數據在增強大模型邏輯推理能力方面的巨大潛力和實際應用價值。