在AI界萬眾矚目的時刻,4月28日深夜至凌晨,Qwen 3模型終于揭開神秘面紗,震撼登場。這款由阿里打造的AI模型,自預熱以來便引發了業內人士的狂熱猜想與期待。
從午后開始,關于Qwen 3即將發布的消息便在各大社交平臺迅速蔓延。Qwen團隊的核心成員林俊旸在社交媒體上微妙地暗示:“今晚,讓我們共同見證Qwen 3的誕生。”這一消息如同一石激起千層浪,讓AI圈瞬間沸騰。
在各大專業討論群組中,關于Qwen 3的傳言與猜測不絕于耳,真假難辨的模型截圖滿天飛。AI從業者們不斷刷新GitHub和HuggingFace上的Qwen主頁,甚至有人利用AI技術生成了Qwen 3上線的模擬海報和現場圖,各種表情包刷屏,狂歡氛圍直至深夜仍未消散。
終于,在凌晨5點,Qwen 3如約而至。這款新模型不僅參數量僅為DeepSeek-R1的三分之一,實現了成本的大幅降低,更在性能上全面超越了R1、OpenAI-o1等全球頂尖模型。這一突破性進展,無疑為阿里在AI領域的布局增添了濃墨重彩的一筆。
更引人注目的是,Qwen 3創新性地搭載了Claude 3.7等頂尖模型的混合推理機制,將“快思考”與“慢思考”完美融合于同一模型中,極大地減少了算力消耗。這一創新設計,不僅提升了模型的智能水平,更降低了使用成本,為AI的廣泛應用開辟了新路徑。
Qwen 3的開源涵蓋了8款不同架構和尺寸的模型,從0.6B到235B不等,適用于多種類型的移動端設備。Qwen還推出了Agents的原生框架,支持MCP協議,展現出了“讓所有人都能用上Agents”的雄心壯志。
回顧阿里在AI領域的歷程,自DeepSeek爆火后的1月份,阿里便迅速上線了新模型Qwen2.5-VL和Qwen2.5-Max,展現了其在AI技術上的強大實力。這一系列動作不僅為阿里集團增添了濃厚的“AI味兒”,更在資本市場上引發了強烈反響,阿里股價在春節前后階段大漲超30%。
然而,與旗艦級模型Qwen 3相比,此前的模型都只是前奏。Qwen系列作為全球領先的開源模型之一,已經贏得了業界的廣泛認可。據最新數據,阿里通義已開源200余個模型,全球下載量超3億次,千問衍生模型數超10萬個,成功超越了此前的開源霸主Llama。
Qwen 3的發布,標志著阿里在AI開源社區的地位進一步鞏固。與DeepSeek的快速沖鋒不同,Qwen更像是一個穩扎穩打的軍團,不僅布局更早,更在生態構建上展現出了強大的活力與覆蓋度。這在一定程度上也成為了大模型落地的產業風向標。
以DeepSeek R1為例,雖然其強大的推理能力令人矚目,但高昂的落地成本卻讓許多企業和個人望而卻步。相比之下,Qwen家族提供了更多尺寸和類別的模型,幫助產業界更快驗證落地價值。尤其是Qwen 13B及以下的模型,因其可控性強、易于應用,成為了AI應用領域的熱門選擇。
在Qwen 3的訓練中,阿里投入了驚人的資源。基于36萬億token進行預訓練,這一數據量遠超上一代模型Qwen 2.5,在全球頂尖模型中名列前茅。據Qwen團隊公布的數據,僅需4張H20顯卡即可部署Qwen 3滿血版,顯存占用僅為性能相近模型的三分之一。
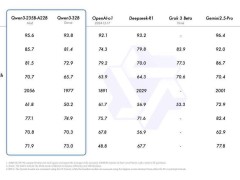
在性能上,Qwen 3同樣表現出色。在數學、代碼生成和常識邏輯推理方面,Qwen 3均超越了先前的推理模型QwQ和Qwen2.5(非思考模式)。同時,在代碼、數學、通用能力等基準測試中,Qwen 3也能與目前的頂尖模型如o3-mini、Grok-3和Gemini-2.5-Pro等一較高下。

除了性能上的提升,Qwen 3的另一個核心亮點是對智能體(Agents)的全面適配。通過混合推理機制,Qwen 3能夠在單一模型內無縫切換思考模式和非思考模式,從而適應不同場景下的需求。這一創新設計不僅提高了模型的智能水平,更降低了算力資源消耗,為用戶帶來了更加流暢和高效的使用體驗。
為了讓更多人能夠輕松開發Agents,Qwen團隊還提供了全面的工具箱支持。包括熱門的MCP協議、原生的Qwen-Agent框架以及封裝了工具調用模板和解析器的API服務。這些工具將大大降低編碼復雜性,使得開發者能夠更高效地實現各種手機及電腦Agent操作任務。
隨著Qwen 3的發布,開源模型領域也迎來了新一輪的競爭周期。在DeepSeek R1之后,各大公司紛紛加大在模型層的技術投入,以期在激烈的競爭中脫穎而出。而Qwen 3的發布,無疑為這一競爭注入了新的活力。