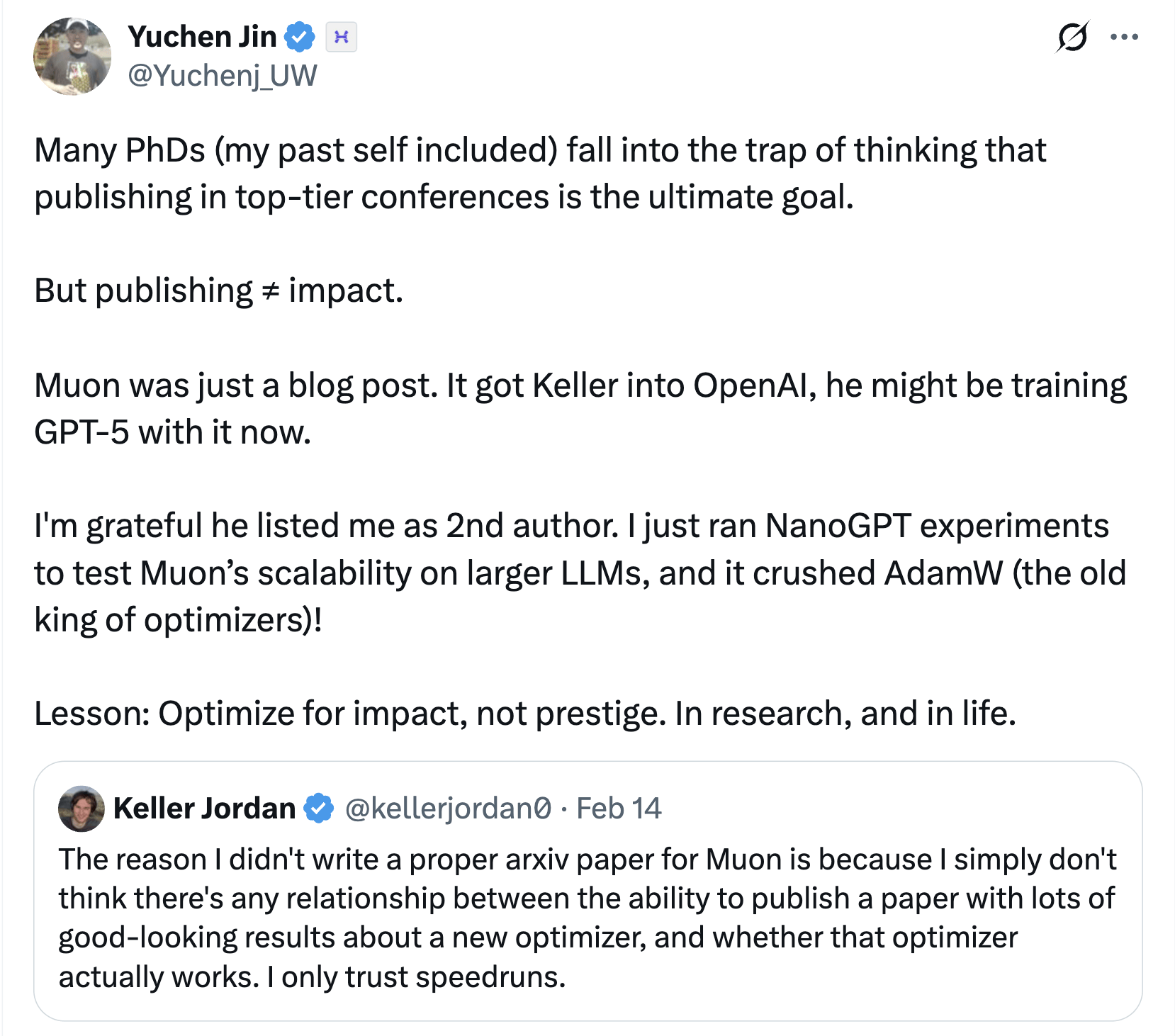
近日,AI領域迎來了一則引人注目的消息。據AI云服務商Hyperbolic的聯合創始人兼首席技術官Yuchen Jin在社交平臺上的爆料,研究員Keller Jordan僅憑一篇博客文章就成功加入了OpenAI,并有可能正在利用文章中提及的神經網絡隱藏層優化器Muon來訓練GPT-5。
Yuchen Jin指出,許多研究人員,包括過去的自己,都曾誤以為在頂級學術會議上發表論文才是最終目標。然而,Keller Jordan用實際行動證明了,發表論文并不等同于產生影響力。他的博客文章《Muon:神經網絡隱藏層的優化器》雖然只是以博客形式發布,卻讓他成功加入了OpenAI。
Keller Jordan的這篇博客發布于2024年12月,詳細介紹了Muon優化器的設計、實證結果及其與先前研究的聯系。Muon是一個針對神經網絡隱藏層二維參數的優化器,它在NanoGPT和CIFAR-10的快速運行中刷新了訓練速度的記錄。具體來說,Muon使用Newton-Schulz矩陣迭代作為后處理步驟,來優化SGD-momentum生成的更新,從而提高了訓練效率。
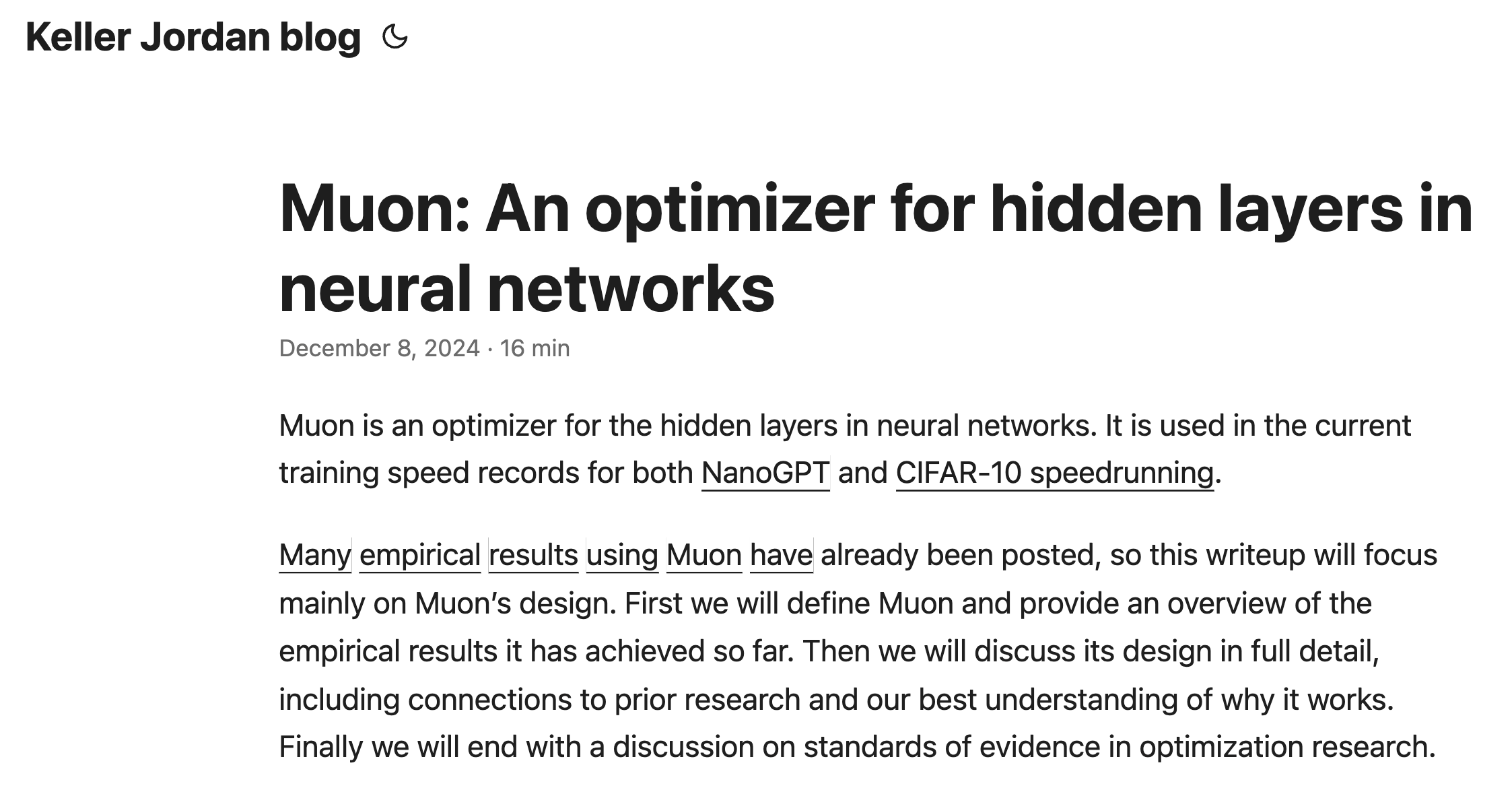
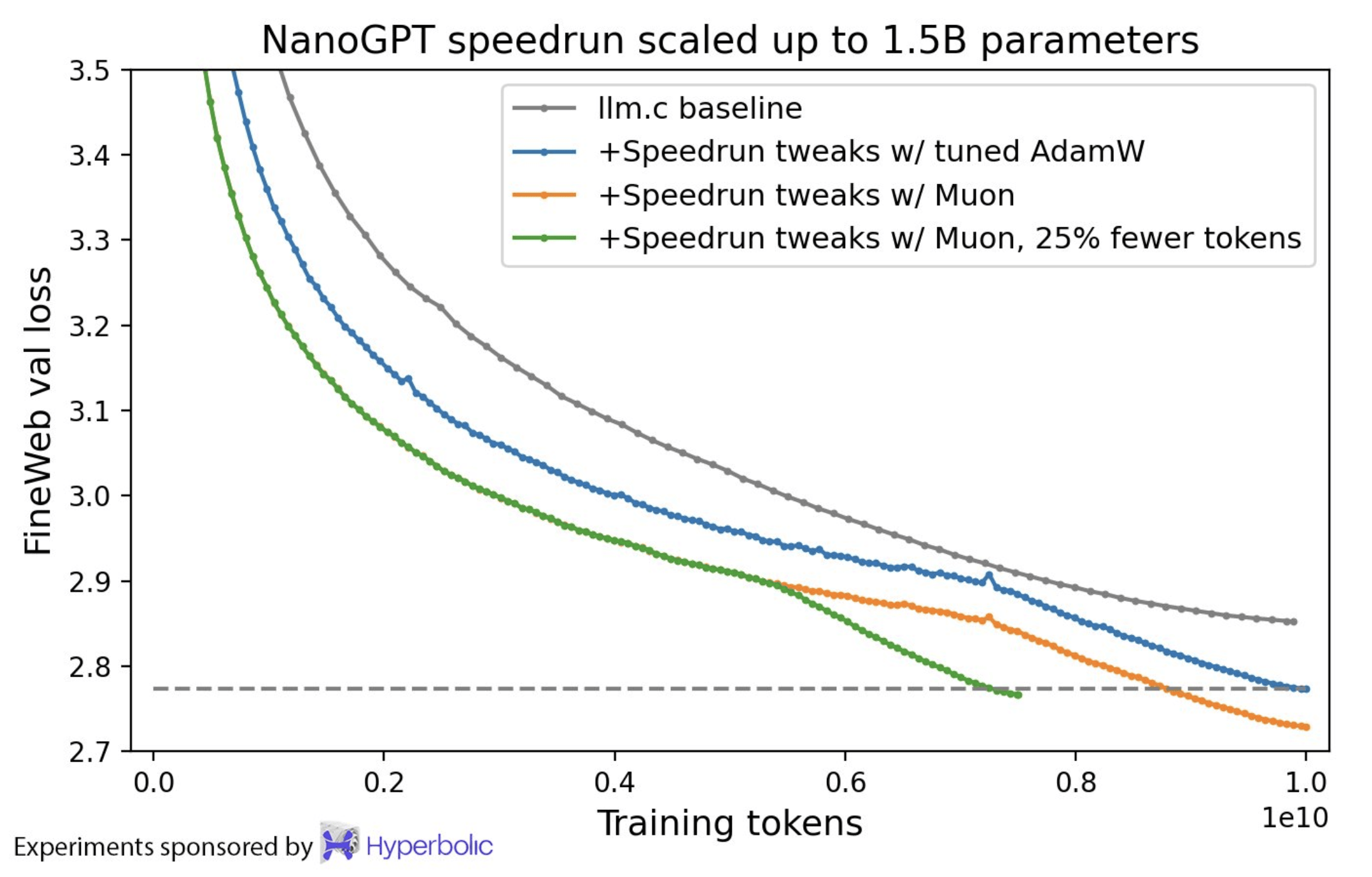
根據Keller Jordan的博客內容,Muon在多個任務上均取得了顯著的實證成果。例如,在CIFAR-10數據集上,它將訓練速度記錄提高到了94%的準確率,并將訓練時間從3.3秒縮短到了2.6秒。Muon還在NanoGPT快速運行的競賽任務FineWeb上刷新了訓練速度記錄,提高了1.35倍。更重要的是,Muon在擴展到更大規模模型時,繼續顯示出了訓練速度的提升。
Keller Jordan在博客中還深入探討了Muon的設計原理,解釋了為什么正交化更新是可行的。他指出,SGD-momentum和Adam等傳統優化器對基于Transformer的神經網絡中的二維參數產生的更新通常具有非常高的條件數,即這些更新幾乎是低秩矩陣。通過正交化這些更新,Muon能夠有效地增加其他“稀有方向”的規模,從而提高學習性能。
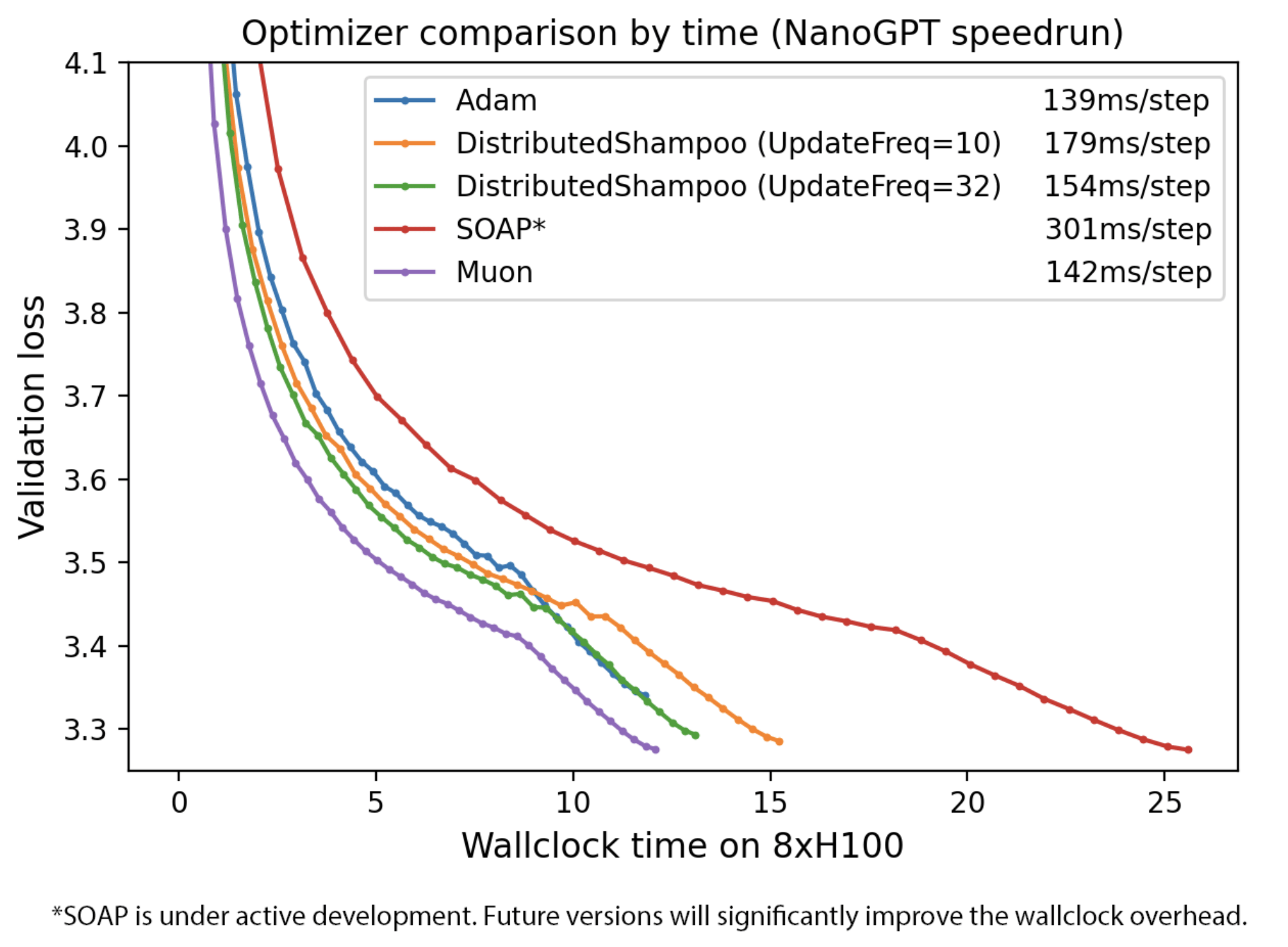
除了設計原理外,Keller Jordan還在博客中提供了Muon與AdamW等標準優化器的對比實驗。實驗結果顯示,在多個任務和數據集上,Muon均表現出了優于AdamW的訓練效率。特別是在訓練大型語言模型時,Muon的FLOP開銷低于1%,卻能夠顯著提高訓練速度。
Keller Jordan的這篇博客不僅引起了學術界的關注,更讓他成功加入了OpenAI。據職場社交平臺領英顯示,Keller Jordan正是在2024年12月加入OpenAI的。由此可以推測,他正是憑借這篇博客中介紹的Muon優化器,成功進入了這家如日中天的頭部大模型企業。
目前,尚不清楚Muon是否已經成為GPT-5訓練中的關鍵技術。但無論如何,Keller Jordan的這篇博客和Muon優化器都已經引起了業界的廣泛關注。隨著OpenAI對GPT-5研究的深入,我們有理由期待Muon能夠在未來的人工智能領域發揮更加重要的作用。