在人工智能大模型領域,階躍星辰公司正逐漸成為不可忽視的力量。業內普遍認可,階躍星辰所具備的基礎模型能力,在國內幾大模型公司中名列前茅。然而,這一評價更多局限于對大模型有深入了解的專業人士中,對于普通大眾而言,階躍星辰的硬實力并不直觀。
不過,階躍星辰在LiveBench榜單上的表現,無疑給行業帶來了巨大沖擊。LiveBench被譽為“世界上首個不可玩弄的LLM基準測試”,其權威性和公正性廣受認可。最新榜單顯示,階躍星辰自研的萬億參數語言大模型Step-2,在國產基座大模型中排名第一,成績直逼OpenAI的頂尖模型,超越了GPT-4等多個國際主流模型,全球排名僅次于OpenAI和Anthropic。
本次榜單中,階躍星辰是唯一進入前十名的中國大語言模型,排名第五。相比之下,同樣上榜的通義千問和深度求索則未能進入前十,分別位列第十三和第二十三名。這一成績無疑彰顯了階躍星辰在底層模型能力上的卓越表現。
在LiveBench的多項測評標準中,Step-2在IF Average(指令跟隨)方面的表現尤為突出,以86.57的高分位居榜首,超越了包括OpenAI最新模型在內的所有國內外語言大模型。這一成績充分展示了Step-2對語言生成細節的強大控制力,以及在復雜指令遵循上的高超能力。
自2024年3月發布國內首個由創業公司研發的萬億參數語言大模型預覽版Step-2以來,階躍星辰在多個領域取得了顯著成就。不僅在中文大模型基準測評機構SuperCLUE上登頂國內多模態大模型榜首,更在本次LiveBench榜單上榮獲中國大模型第一。這些成就充分證明了階躍星辰在提升自身底層實力方面的決心和成效。
基于Step-2萬億參數大模型和Step-1.5V多模態模型能力,階躍星辰的C端產品躍問也迎來了迭代升級。躍問推出的“拍照問”功能,通過圖像交互實現了“即拍即問”,解決了文字和語音交互中難以準確描述的痛點,贏得了用戶廣泛好評。目前,Step-2已經接入躍問APP和網頁端,開發者可以通過API接入使用。
LiveBench榜單的含金量不言而喻。作為由AI科學家楊立昆等聯合推出的權威基準測試,LiveBench包含6大類18項任務,以全面、客觀、公正著稱。每月發布新問題,并根據最新數據集、論文、新聞和電影簡介設計問題,以避免數據污染。其評價體系中立,能夠準確評估模型在數學、推理、編程、語言理解、指令遵循和數據分析等多個維度上的表現。

Step-2在IF Average指標上的碾壓表現,充分展示了其在指令跟隨能力上的卓越。指令跟隨能力衡量的是模型對語言生成細節的控制力,以及滿足限定要求的能力。在文學創作領域,Step-2能夠根據用戶指令精確調整和優化文本,如在創作古詩詞時精準把握字數、格律、押韻和意境。例如,在躍問中輸入創作一首主題為“愛而不得”的七言律詩,Step-2能夠準確捕捉意境并輸出押韻的古詩。

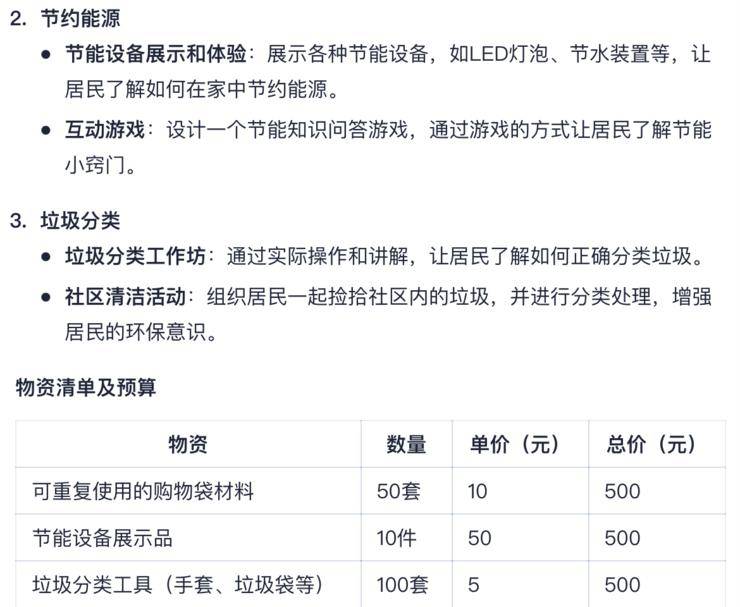
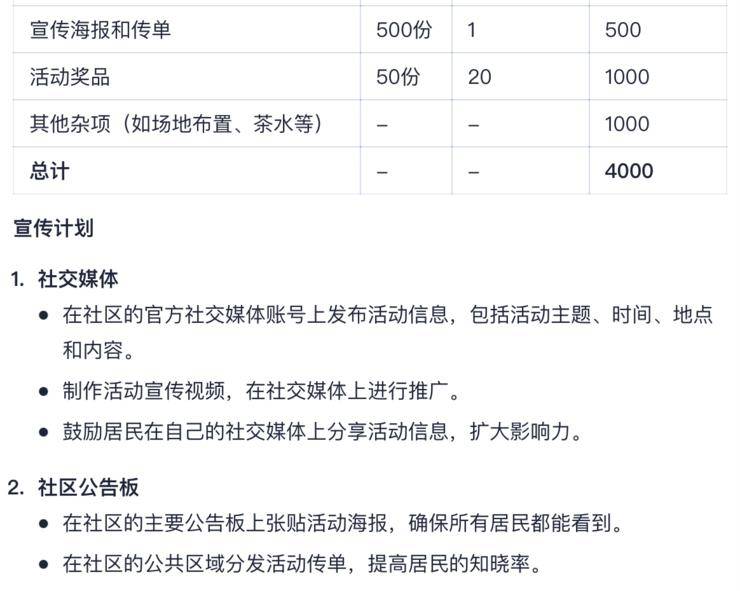
在應對復雜prompt的多項細節指令時,Step-2同樣表現出色。例如,設計一個為期一周的社區環保活動計劃,Step-2能夠全面考慮活動安排、主題、互動環節、物資清單、預算、宣傳方式以及安全措施等多個方面,確保無一遺漏。



Step-2的出眾指令跟隨能力背后,是其強大的理解和推理能力支撐。同時,龐大的數據量也是其能力強悍的關鍵因素。Step-2的知識覆蓋范圍和深度顯著突破,能夠處理常見領域知識,還能深入理解和回答特定領域或邊緣分布中的復雜問題。
開發出萬億參數模型是各大模型公司發展的里程碑。階躍星辰在短短一年內成功發布Step-2語言大模型預覽版,成為國內首個由創業公司發布的萬億參數模型。Step-2采用MoE架構,通過部分專家共享參數、異構化專家設計等創新設計,每個“專家模型”都得到充分訓練。在訓練過程中,階躍星辰系統團隊突破了多項關鍵技術,具備領先的系統能力以支持高效訓練。
然而,階躍星辰的雄心遠不止于萬億參數的大語言模型。Step-1.5V多模態大模型在視頻理解、感知能力等方面表現出色,能夠準確識別視頻中的物體、人物和環境,理解視頻氛圍和人物情緒。Step-1X圖像生成大模型則具備更強的深度語義對齊能力和細節生成能力,能夠生成豐富細節和逼真質感的圖像,尤其擅長處理富含中國元素的內容。
在扎實底層模型的基礎上,階躍星辰的產品開發更具底氣。躍問智能助手中的“拍照問”功能,就是基于基礎模型能力推出的創新功能,能夠解決難以用語音和文字準確描述的問題。隨著基礎模型能力的不斷提升,階躍星辰的產品能力也將進一步延展。