在人工智能領域,一項新的技術突破近日引起了廣泛關注。由Hugging Face、英偉達及約翰霍普金斯大學的專家攜手打造的ModernBERT模型,正式對外發布。這一創新成果,是對BERT模型的進一步優化與升級,旨在提升處理效率,同時增強對長文本上下文的理解能力。
ModernBERT的卓越表現,得益于其龐大的訓練數據量——超過2萬億個Token的洗禮。這一龐大的訓練基礎,使得ModelBERT在分類任務和向量檢索任務中,均展現出了非凡的實力,刷新了行業內的多項記錄。
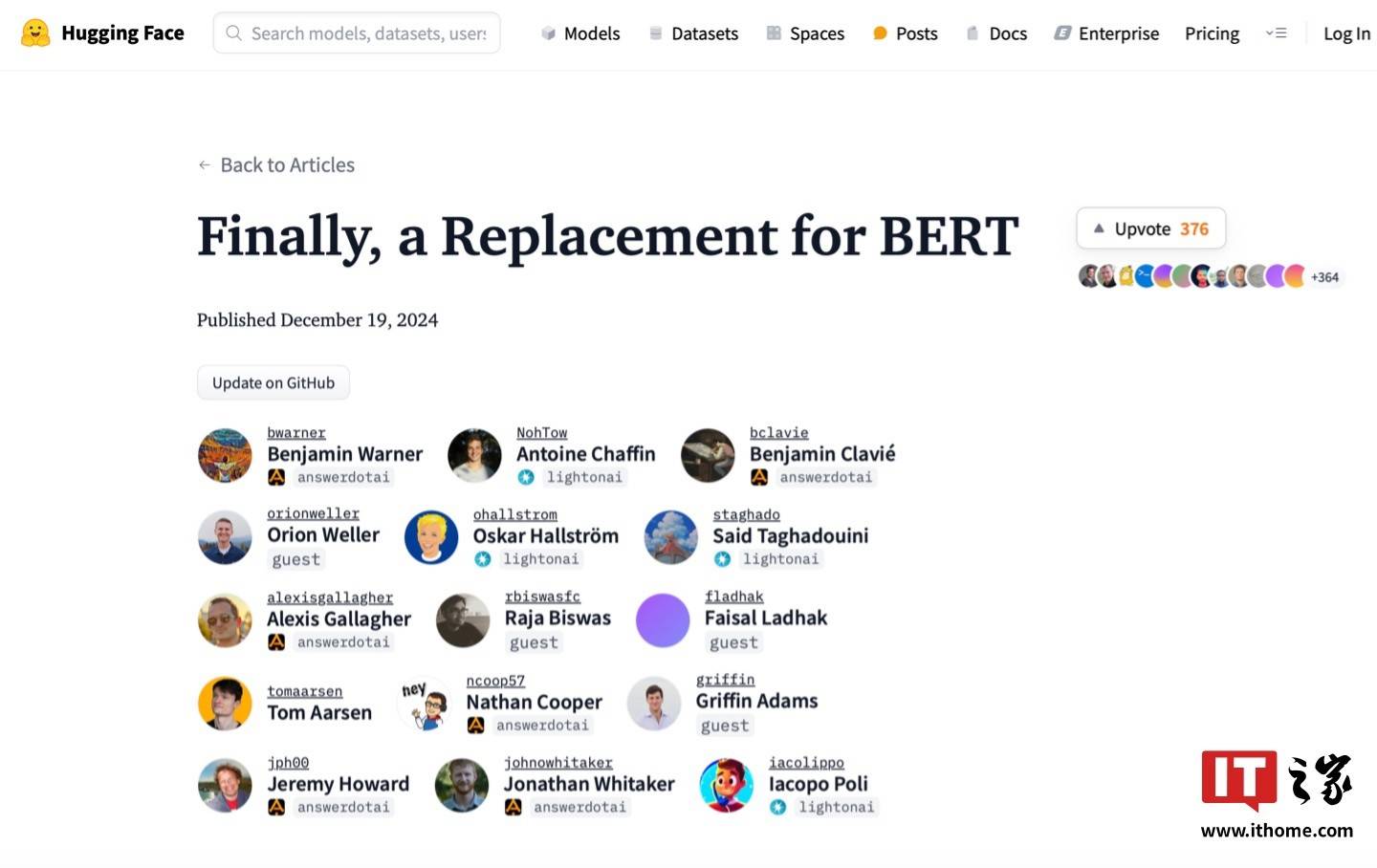
為了滿足不同場景下的應用需求,ModernBERT提供了兩個版本的模型供用戶選擇。其中,輕量級版本擁有1.39億參數,而更為強大的版本則配備了3.95億參數。這兩個版本均展現了極高的性能,為用戶提供了靈活的選擇空間。
值得注意的是,ModernBERT項目不僅技術領先,而且極具開放性。目前,該項目已經正式上線,用戶可以通過相關渠道免費下載并使用這一先進的模型。這一舉措無疑將極大地推動人工智能技術在各個領域的應用和發展。
對于對ModernBERT感興趣或希望深入了解其技術細節的讀者來說,可以通過官方渠道獲取更多信息。這一創新成果的發布,無疑為人工智能領域注入了新的活力,也為未來的技術發展提供了更多的可能性。